Java笔记-集合
Java笔记-集合专题
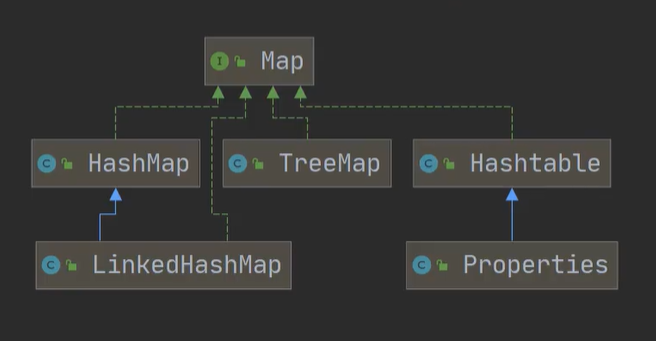
集合体系图
集合主要分为两种:
Collection: List、Set;属于单列集合
Map:双列集合,存放Key-Value

Collection
这些是List和Set都继承了的方法。
1 | |
遍历Collection
1 | |
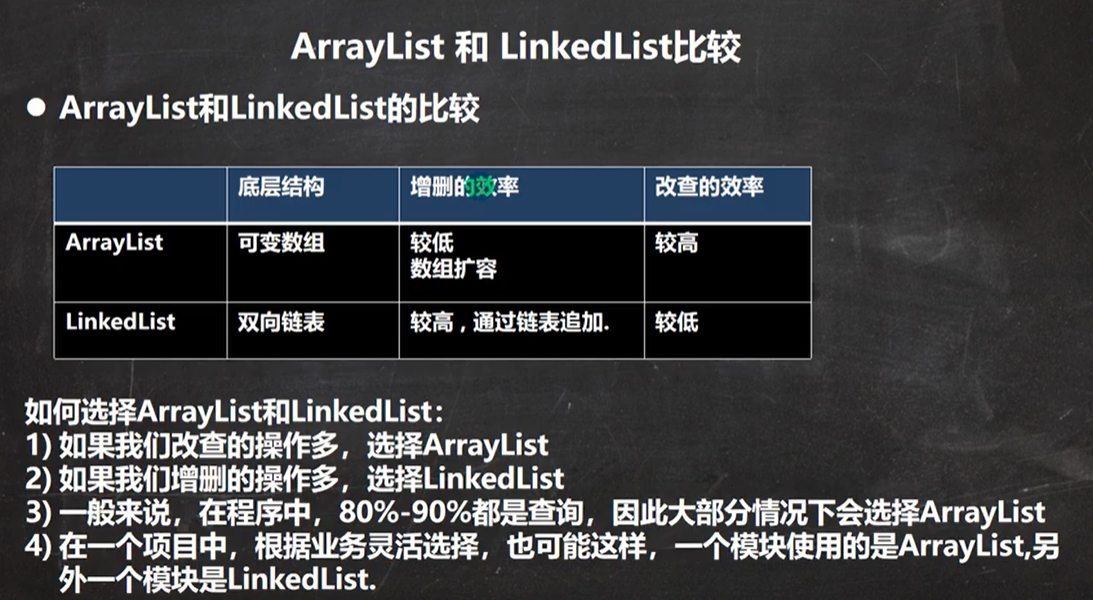
ArrayList底层

上面的transient表示:被修饰的属性是瞬间的,短暂的,不会被序列化。
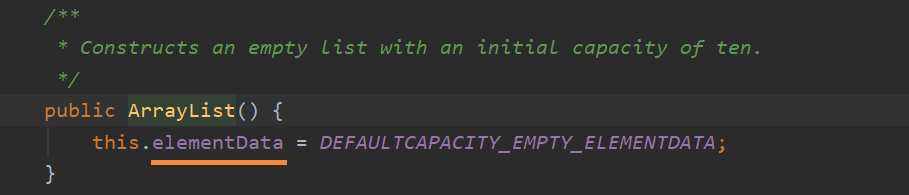
使用无参构造器创建ArrayList:
1 | |
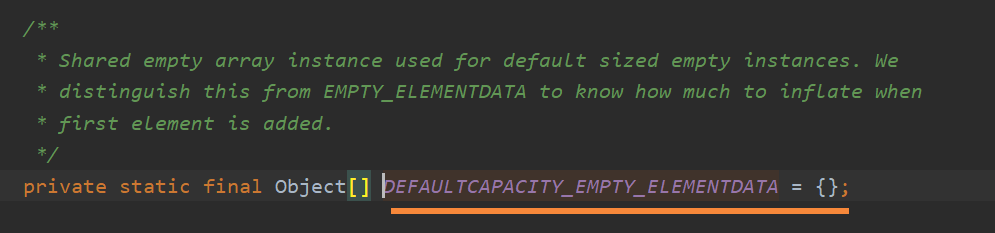
使用无参构造器,首先创建了一个空的elementData数组;从这里可见:ArrayList的底层是通过数组实现的,而这个elementData就是存放数据的数组。
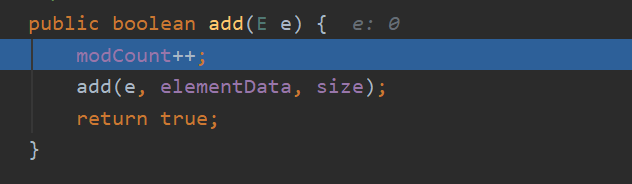
然后我们看添加元素的方法:
e:代表要添加的元素;
modCount:记录集合被修改的次数
在这个add中其实调用了另一个add方法,而这第二个是真正实现添加操作的。
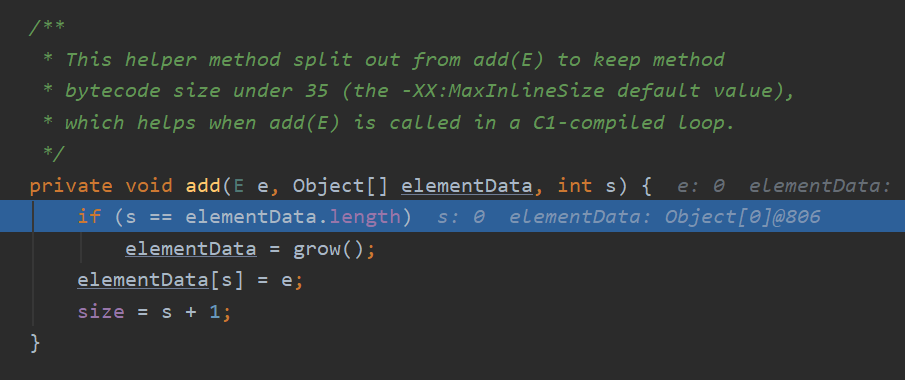
s:指示在ArrayList中添加的元素个数;
elementData.length:表示当前的容量;
当两者相等,表示当前容量不够,需要自动增加容量了。–>grow()
确保有剩余的空间来添加元素后,才进行真正的添加元素:
elementData[s]=e; //添加到尾部
size = s+1; //更新元素个数
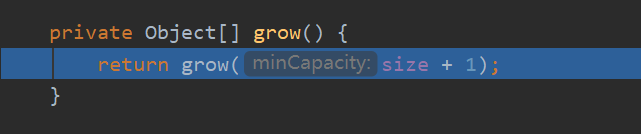
s==elementData.length:需要扩容时
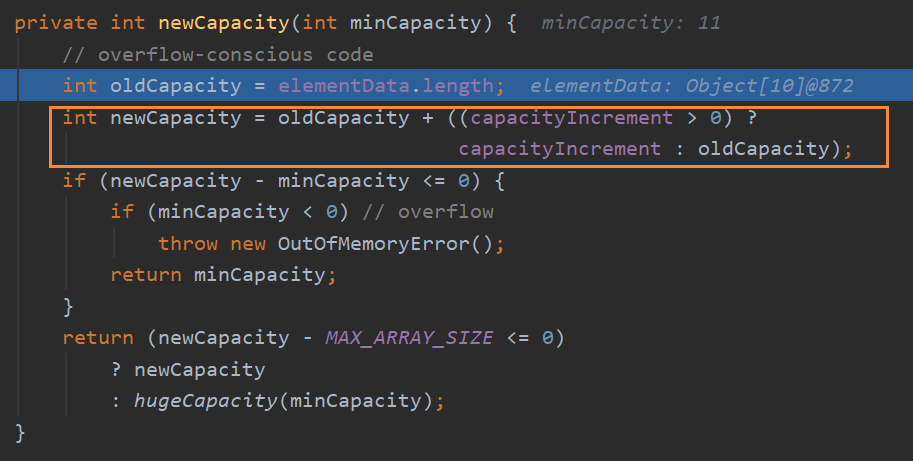
扩容的方法:
minCapacity:指示当前ArrayList所需要的最小容量,添加当前这个元素所需要的容量。
newCapacity():计算自动扩容后的容量
扩容:将原数组复制到一个更大的数组–》Array.copyOf(),这样可以保留原先的数据

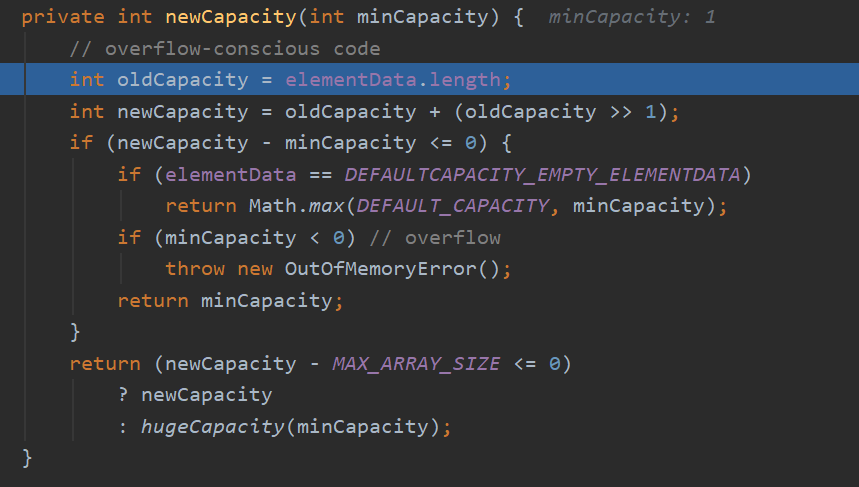
最后看下扩容的容量是怎么算的–》newCapacity()
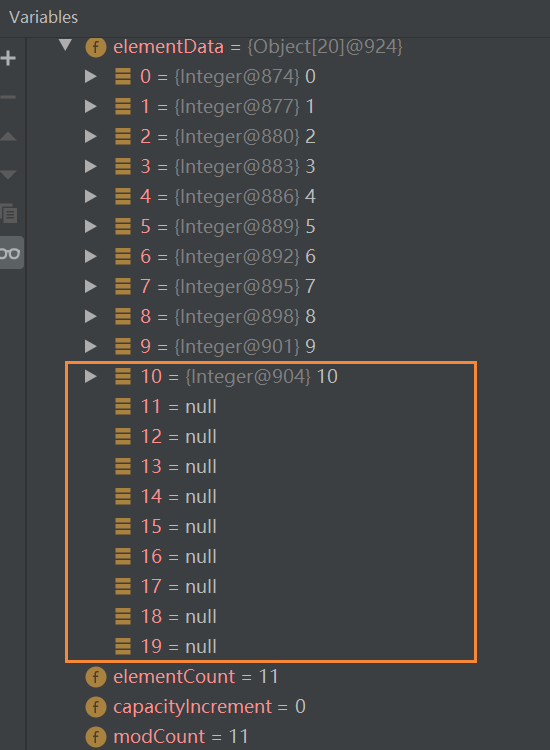
第一次扩容情况特殊,通过方法中第二条语句计算得到的newCapacity仍然是0,所以要通过下面的判断来进行特殊处理。
后面的就是按照:newCapacity = oldCapacity + (oldCapacity>>1); // 等价于扩容到原来容量的1.5倍
1 | |
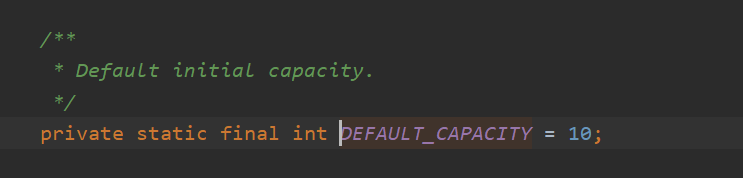
使用带参构造器
使用带参数的构造器时,elementData的默认容量就是所传的参数,后面容量的自动增长也是增加到原来的1.5倍。
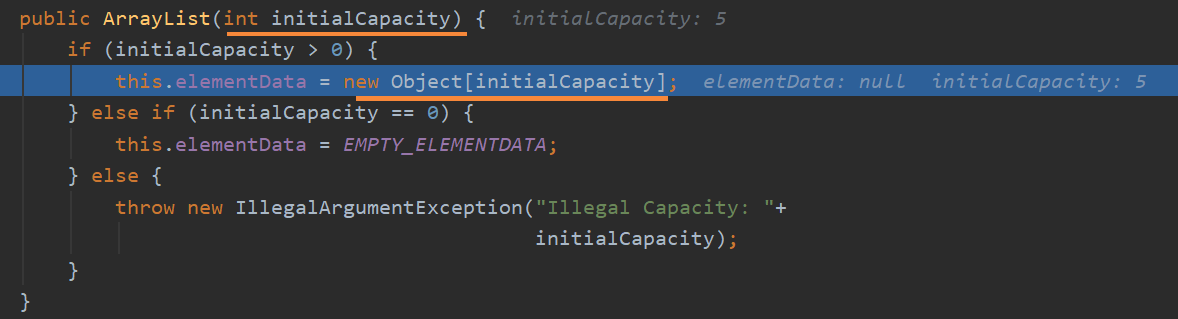
Vector底层
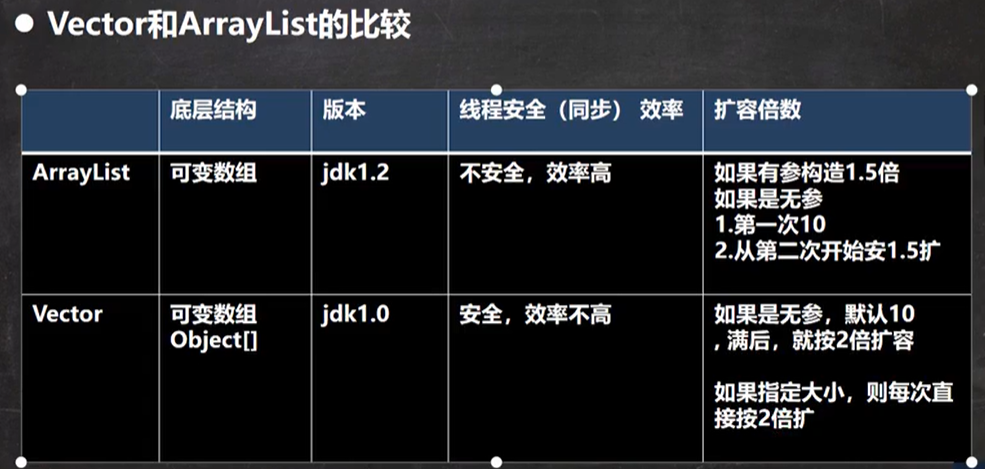
无参构造器
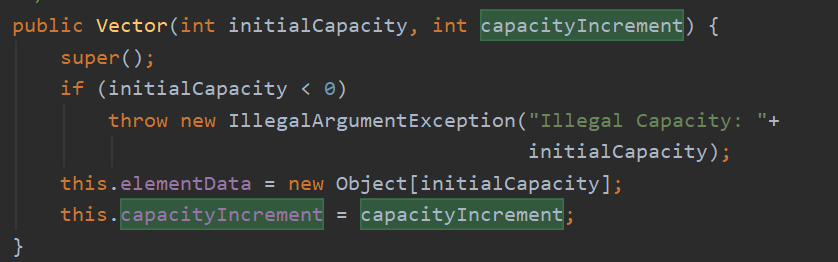
从源码中,我们可以看到,不管我们使用的是有参还是无参的构造器,它最终都是通过Vector(int initialCapacity, int capacityIncrement)实现的;而且使用无参构造器,实际是创建了一个默认容量为10的Vector。


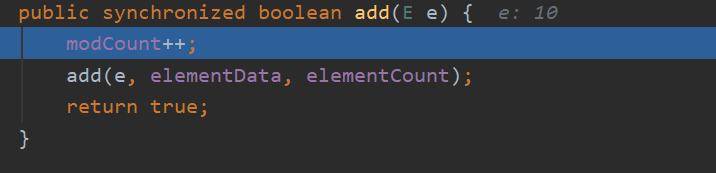
我们再来看下add()方法,感觉和ArrayList的add()很类似,不同的是,Vector扩容时,时扩容到原来的2倍。



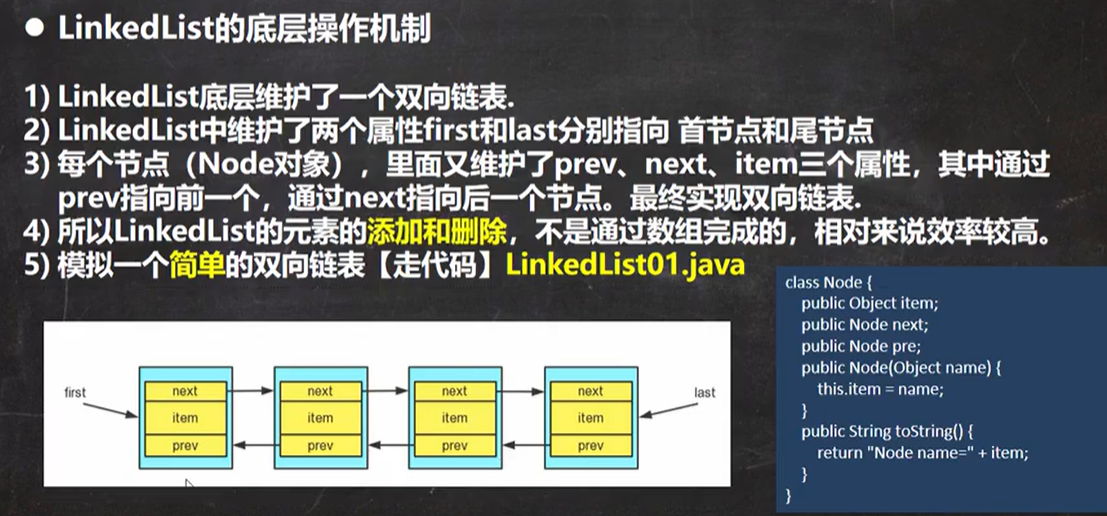
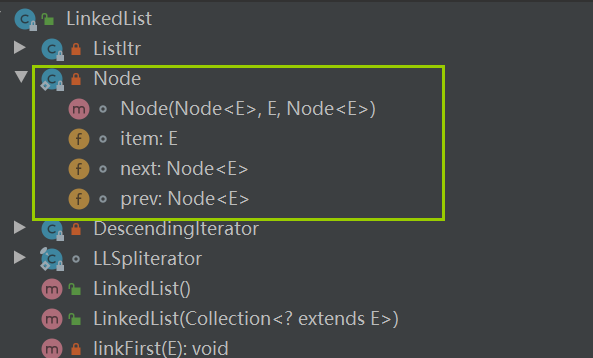
LinkedList底层
底层实现了双向链表和双端队列的特点。
线程不安全,没有实现同步。
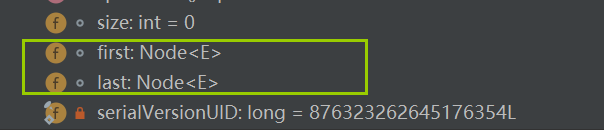
1 | |
构造器
首先看下LinkedList的构造器,就是一个空的方法。执行后给属性进行初始化工作。


add()


添加第一个元素时,链表的头尾指针都是指向这个元素。

试着再添加一个元素,可以看到他们确实形成了双向链表的结构。


remove()



checkElementIndex()是检查所要删除的元素下标是否是有效的。
unlink(Node

Set
Set和List一样,都继承自Collection,所以常用方法和Collection一样。
遍历方式也一样,但是不能使用【索引】的方式来遍历,因为Set中元素是无序的。底层的实现不再是数组,而是数组+链表。
不能存放重复的元素;
是无序的:添加的顺序与取出的顺序不同,但是每次取出的顺序是固定的;
HashSet
HashSet底层是HashMap,-》
(数组+链表+红黑树)jdk8.0
(数组+链表)jdk7.0

LinkedHashSet
其底层是LinkedHashMap;(和HashSet维护的是HashMap结构)
底层维护一个数组+双向链表;
由于有了双向链表,这样就可以让插入顺序与取出的顺寻一致;(和HashSet不同)
Map


HashMap
初始大小16,
加载应子:0.75
Hashtable
key、value均不允许为空,NullPointerException;
是线程安全的;

底层:Hashtable$Entry[],初始大小:11;
当count>=threshold时,
扩容算法:new = (old<<2)+1;新容量 = 原来的*2+1;

Properties

总结

本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!