SQL入门篇
SQL入门篇
这篇是我在牛客网上做SQL题时记录的,到真正做题时才发现对数据库的知识已经忘了好多了🤣🤣
温故而知新,记录自己做不出来的题,方便常常回顾。
SQL3 查询结果去重
主要是两种思路:
1 | |
SQL4 查询结果限制返回行数
主要使用LIMIT关键字,它可以接两个参数,也可以接一个:
1 | |
1 | |
SQL8 查询某个年龄段的用户信息
可以只用between and关键字但是不同的数据库其含义有些许不同,在我测试的MySQL中是左右都是闭区间。

当然可以使用and来连接两个条件。
SQL10 用where过滤空值
1 | |
SQL13 where in 和 not in
使用in或者not in关键字,可以实现判断:某个元素是否在一个集合中。
1 | |
SQL15 查看学校名称中含北京的用户
通过like关键字,进行字符串模式匹配;
复习下字符串匹配:
1 | |
1 | |
SQL19 分组过滤
当聚合函数作为筛选条件时,不能使用where,而是having✅
换句话说,where后面不能接聚合函数
聚合函数:
- count()
- avg()
- sum()
- max()
- min()
聚合函数使用:通常和分组函数group by结合使用
- select子句的选择列表
- having子句
- compute或compute by子句
1 | |
SQL23 统计每个学校各难度的用户平均刷题数
因为需要按照不同难度和学校统计:order by u.university, q.difficult_level
1 | |
SQL25 查找山东大学男生的GPA
组合查询
分别查看学校为山东大学或者性别为男性的用户的device_id、gender、age和gpa数据,请取出相应结果,结果不去重。
注意题目要求是:不去重
如果是直接使用or关键字是会去掉重复的结果的;
这里就需要使用我们一个新的关键字了:UNION ALL
1 | |
SQL26 计算25岁以上和以下的用户
CASE函数
类似编程语言中的if…else或者是case
有两种语法形式:
1 | |
用途:
结合分组进行统计
例如需要统计25岁以上的人数以及25岁以下的人数,也就是这道题目的问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15SELECT
(
CASE
WHEN age >= 25 THEN '25岁及以上'
ELSE '25岁以下'
END
) age_cnt,
COUNT(id) number
FROM user_profile
GROUP BY
(
CASE
WHEN age >= 25 THEN '25岁及以上'
ELSE '25岁以下'
END)1
2
3
4# if判断
SELECT IF(age<25 OR age IS NULL,'25岁以下','25岁以及上') age_cut,COUNT(device_id) Number
FROM user_profile
GROUP BY age_cut分条件更新字段值
例如:将工资低于3000(包含3000)的员工涨幅工资20%,工资等于高于3000的员工涨幅8%
1
2
3
4
5
6
7update t_salary
set salary = (
case
when salary > 3000 then salary + salary * 0.08
when salary <= 3000 then salary + salary * 0.2
end
)检查表中字段值
1
2
3
4
5
6
7select name, (
case
when des in (select des from table_2) then '一致'
else '不一致'
end
)
from table_1行列转换
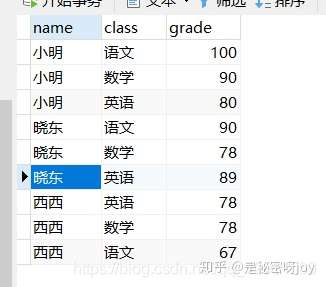
1
2
3
4
5
6
7
8
9// 使用搜索case函数
SELECT NAME,
max( CASE WHEN class = '语文' THEN grade ELSE 0 END ) 语文,
max( CASE WHEN class = '数学' THEN grade ELSE 0 END ) 数学,
max( CASE WHEN class = '英语' THEN grade ELSE 0 END ) 英语
FROM
t_source
GROUP BY
NAME
普通case和搜索case的区别
1、简单case函数判断条件只能是等于,而搜索case函数的条件可以是子查询,In,大于、等于等等。
2、如果只是使用简单的条件分组,可以选择普通case函数,如果需要判断更多的场景,则选择搜索case更好。
SQL28 计算用户8月每天的练题数量
这里主要使用了几个日期的函数:
YEAR()
MONTH()
DAY()
1 | |
SQL29 计算用户平均次日留存率
这道题目还是有点难度的,通过查看题解和讨论总结了两种方法。
首先需要指导平均次日留存率的公示:p = (第一天和第二天都访问过的用户数)/(第一天访问过的用户数)
值得注意的是:可能一个用户两天中都访问过好几次,但是这仍然是一次留存,所以需要使用DISTINCT关键字。
方法一:用原始表左连接处理后的表,这个处理后的表是查询出所有用户在原始的访问日期加了一天的情况,最后的连接条件是设备id相同,而且日期相同。
1 | |
方法二:相比前者,这个更好理解一些。核心思想是让两个表自连接,连接条件是device_id相同,而且表1的日期+1天等于表1的日期。
1 | |
文本函数
- 长度:length(str)
- 连接:concat(str1, str2)
- 分割:SUBSTRING_INDEX(str, 分隔符, 位置)
- 定位:INSTR(substr, str)
- 截取:substring(str, index_begin, len)
窗口函数
SQL33 找出每个学校GPA最低的同学
方法一:使用窗口函数
函数的含义为先分组再排序, row_number() over (partition by col1 order by col2),
表示根据col1分组,在分组内部根据col2排序
1 | |
方法二:使用子查询
1 | |
SQL34 统计复旦用户8月答题情况
首先就有这些条件:
- 连接两个表device_id相等:u.device_id = qp.device_id
- 只统计复旦大学:u.university = ‘复旦大学’
- 时间是8月:YESR(date)=’2021’ AND MONth(date)=’08’
其次我们不仅需要统计做得总题目数还需要统计正确的题目数:
- 总题:COUNT(*)
- 正确题目数:SUM(if(qp.result=’right’),1,0)
按照device_id列进行聚合:GROUP BY u.device_id
1 | |
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!