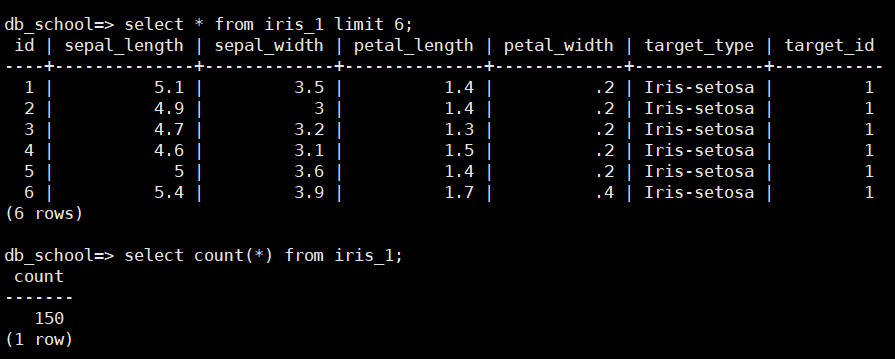
CREATEVIEW iris_random AS SELECT*, ROW_NUMBER() OVER () AS row_num, COUNT(*) OVER () AS total_rows FROM iris_1 ORDERBY RANDOM();
CREATEVIEW iris_train AS SELECT* FROM iris_random WHERE row_num <= total_rows *0.8;
CREATEVIEW iris_test AS SELECT* FROM iris_random WHERE row_num > total_rows *0.8;
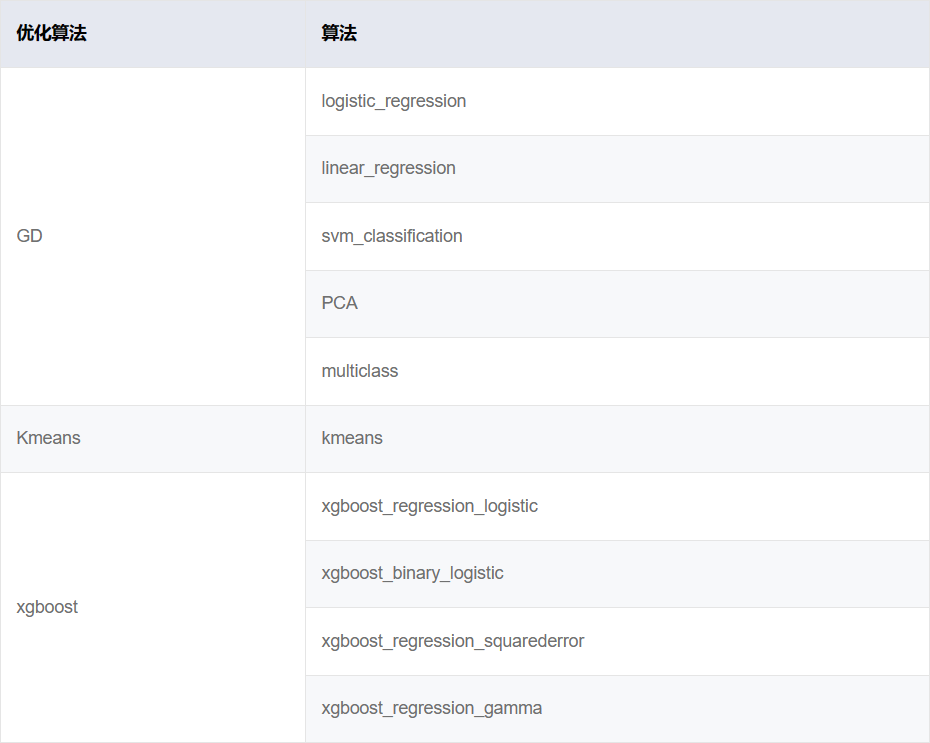
二分类模型
假定我们现在的目标是要区分是否为山鸢尾,这是一个二分类问题,这里我们选择使用逻辑回归来解决。
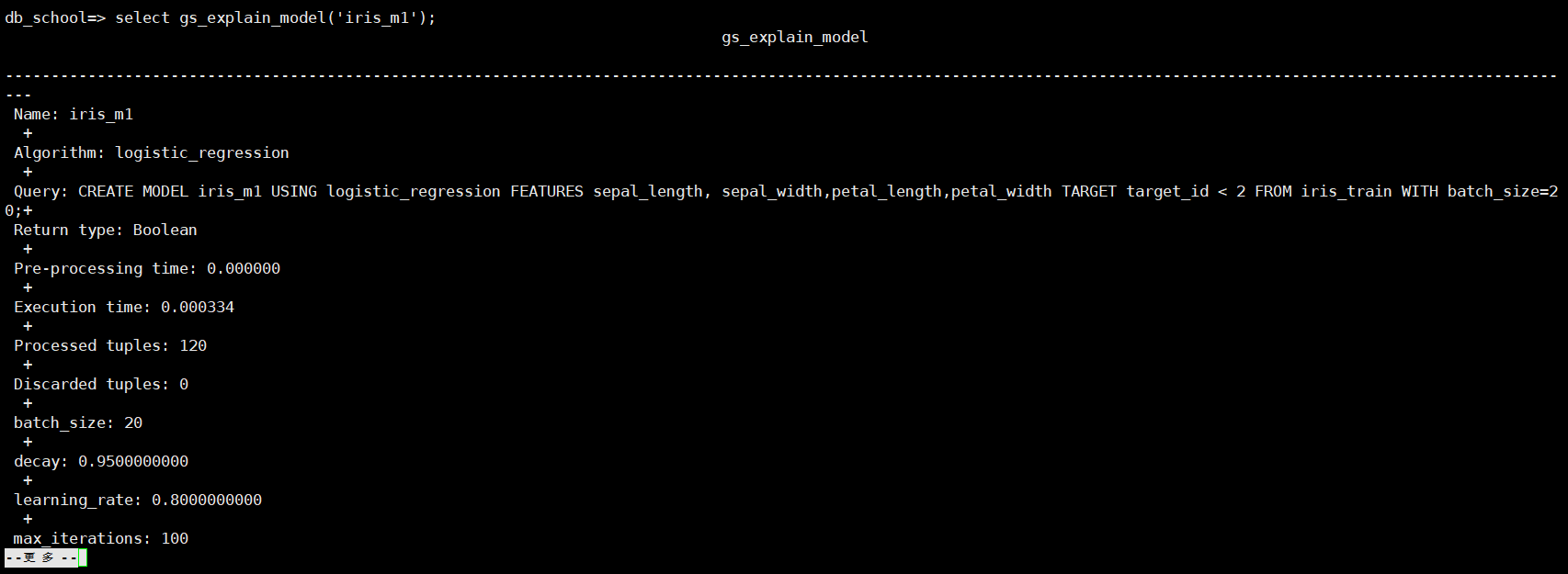
CREATE MODEL
1 2 3 4 5
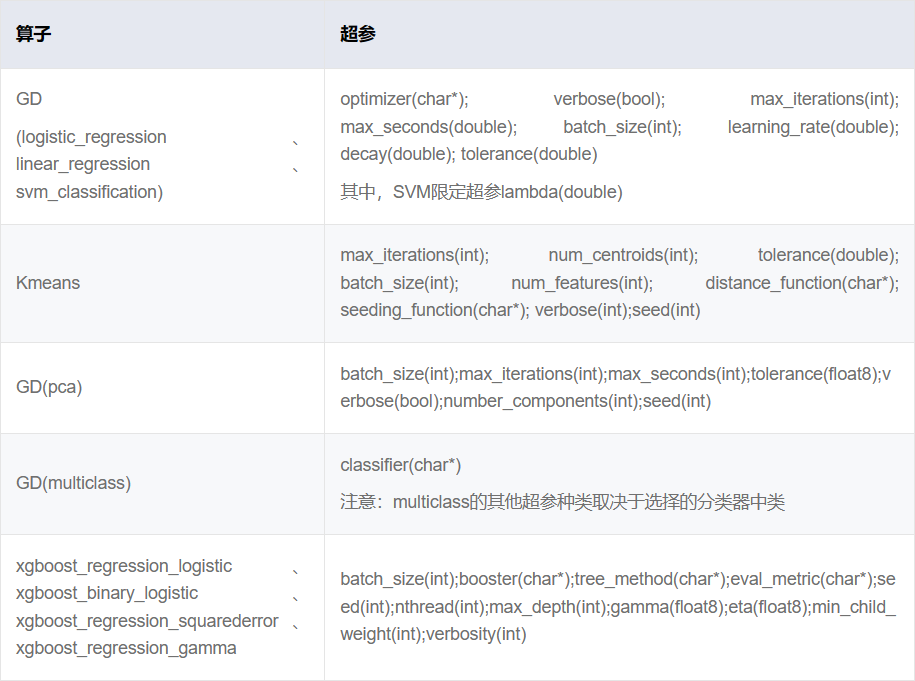
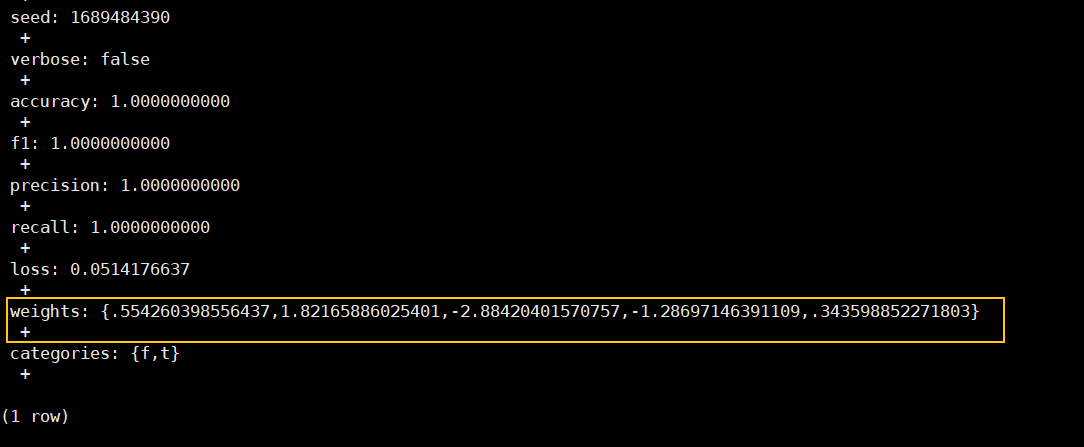
CREATE MODEL iris_m1 USING logistic_regression FEATURES sepal_length, sepal_width,petal_length,petal_width TARGET target_id <2 FROM iris_train WITH batch_size=20;
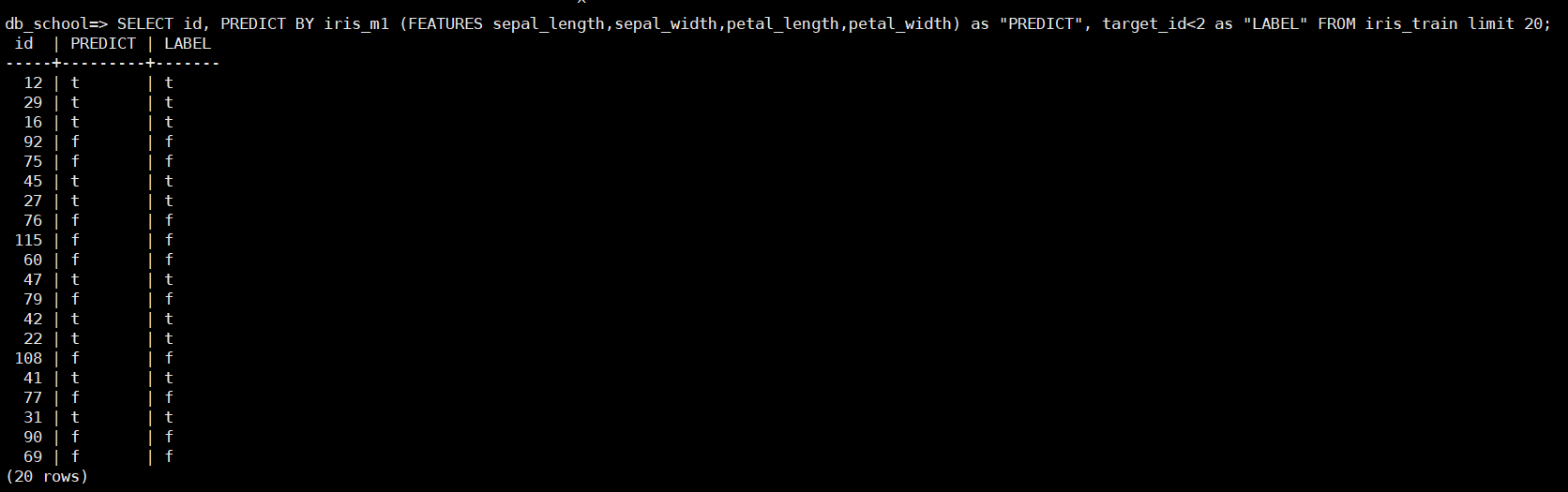
SELECT id, PREDICT BY iris_m1 (FEATURES sepal_length,sepal_width,petal_length,petal_width) as "PREDICT", target_id <2as "LABEL" FROM iris_train limit 20;
1 2 3 4
SELECT id, PREDICT BY iris_m1 (FEATURES sepal_length,sepal_width,petal_length,petal_width) as "PREDICT", target_id <2as "LABEL" FROM iris_test;
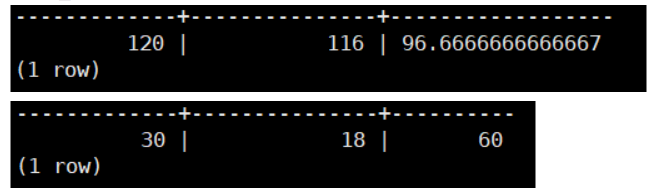
计算分类准确率
1 2 3 4 5 6 7 8 9 10 11 12 13 14
SELECT id, PREDICT BY iris_m1 (FEATURES sepal_length,sepal_width,petal_length,petal_width) as "PREDICT", target_id <2as "LABEL" INTO temp_pred FROM iris_train limit 20;
SELECT COUNT(*) AS total_count, SUM(CASEWHEN "PREDICT"= "LABEL" THEN1ELSE0END) AS correct_count, CASE WHENCOUNT(*) =0THEN0.0 ELSE (SUM(CASEWHEN "PREDICT" = "LABEL" THEN1ELSE0END)::FLOAT/COUNT(*)) *100.0 ENDAS accuracy FROM temp_pred;
CREATE MODEL iris_m2 USING multiclass FEATURES sepal_length, sepal_width,petal_length,petal_width TARGET target_id FROM iris_train WITHclassifier="logistic_regression", batch_size=20,max_iterations=300,learning_rate =1.0;
droptable temp_pred;
SELECT id, PREDICT BY iris_m2 (FEATURES sepal_length,sepal_width,petal_length,petal_width) as "PREDICT", target_id as "LABEL" INTO temp_pred FROM iris_test;
SELECT COUNT(*) AS total_count, SUM(CASEWHEN "PREDICT"= "LABEL" THEN1ELSE0END) AS correct_count, CASE WHENCOUNT(*) =0THEN0.0 ELSE (SUM(CASEWHEN "PREDICT" = "LABEL" THEN1ELSE0END)::FLOAT/COUNT(*)) *100.0 ENDAS accuracy FROM temp_pred;
batch_size=20 经过调节超参数batch_size=4,在训练集上的结果可以提升
小结
最后总结下在使用openGauss中AI模块的流程
处理数据集
数据集中的每个样本通常包括多个属性列和标签列,建议添加一个id列用于标识每个样本
划分数据集,在ML中需要在训练集上训练模型,在测试集上评估
明确属于是哪种任务类型(分类or回归),才能选择后面相应的算法
创建模型
CREATE MODEL关键字创建模型
DROP MODEL xxx; 删除模型
SELECT gs_explain_model(‘xxx’); 查看模型详细信息
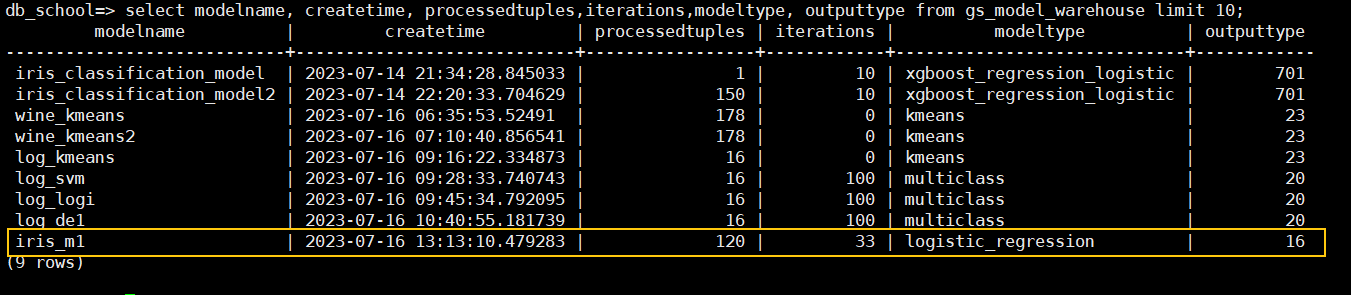
SELECT modelname, createtime, processedtuples,iterations,modeltype, outputtype FROM gs_model_warehouse LIMIT 5;查看数据库中所有模型