调研-边缘部署大模型
边缘设备
- 边缘计算的优势:低延迟、低带宽操作和隐私保护。
- 边缘计算设备的特点:有限的计算能力、低功耗、丰富的硬件接口以及小巧轻便。
常见的一些边缘设备产品有:英伟达的Jetson系列、华为昇腾310、寒武纪思元220等,除了这类物联网设备外,像手机、PC、车机、头显、云端中的边缘服务器都可以叫做边缘设备。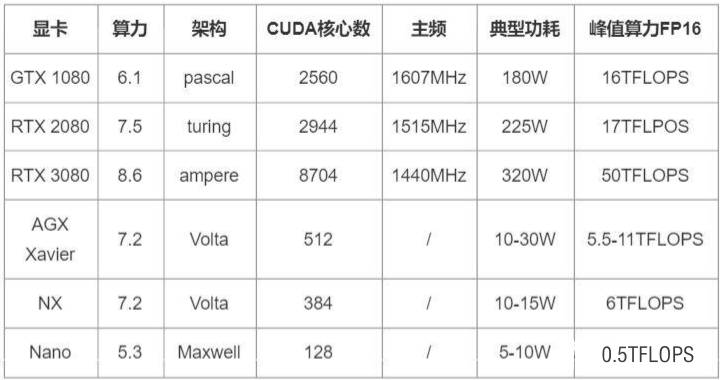 “英伟达云-边显卡性能对比”)
“英伟达云-边显卡性能对比”)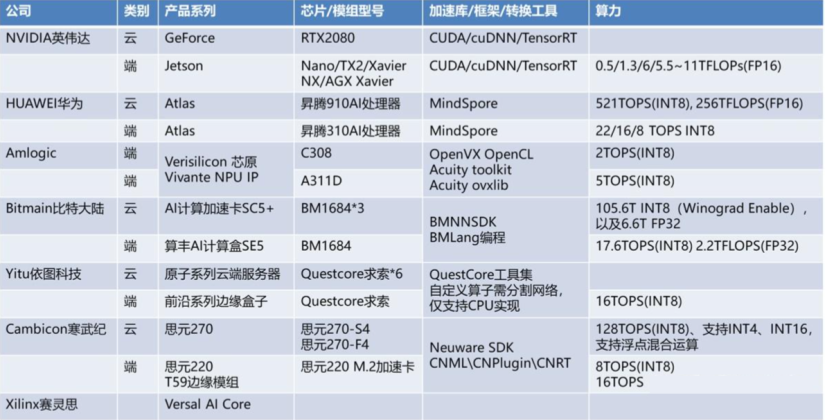 “边缘计算设备对比”)
“边缘计算设备对比”)
大模型
大模型直观上理解就是模型的参数量大,训练数据量大
网络上讨论的大模型大多是指生成式的大语言模型(LLMs),例如ChatGPT,文心一言,可以根据用户输入的提示(prompt)来输出对话。
参数量到底多大才叫大模型?
Github上一篇调查有统计目前LLMs的参数量
可以看到已知最大的模型已经达1200B(12万亿)的参数量,目前最强的GPT4虽然没有公布但有人推测也达到了1700B
大家常用的ChatGPT (based on GPT3)有175B,所以如果想要自己开发一个LLM,没有10B的参数量不好意思叫自己是大模型。
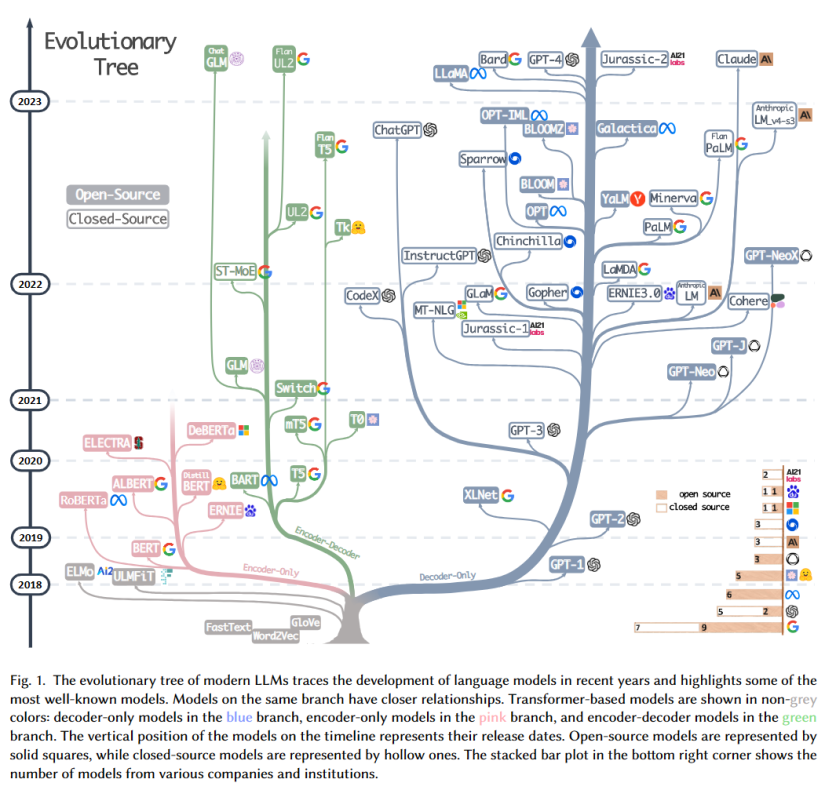 “LLMs的发展过程”)
“LLMs的发展过程”)
使用大模型进行推理需要多少算力
以Llama2-70B举例,假设模型中数据是16bit精度
那么需要2Byte*70B = 140 GB的内存
而在实际上也需要至少2块Tesla A100 GPUs (80G)来进行模型推理或微调
视觉大模型LVMs
一些LVMs例子:
CLIP:由OpenAI开发的CLIP(对比语言-图像预训练)是一个视觉语言模型,经过训练可以结合自然语言理解图像。例如图像标题生成、文本引导图像生成、文本引导图像操作以及视觉问答等。
Google’s Vision Transformer:也称为ViT,是一种图像分类模型,在图像补丁上采用transformer的架构。将图像分割成固定大小的块,然后线性嵌入每个块,添加位置嵌入,并将生成的矢量序列馈送到标准Transformer编码器。现在,这是基于22B个参数进行训练的。
SAM:是由Meta在2023年4月发布的图像分割大模型。其在1100万张图像上训练,实现了强大的零样本泛化。许多研究人员认为「这是 CV 的 GPT-3 时刻,因为 SAM 已经学会了物体是什么的一般概念,甚至是未知的物体、不熟悉的场景(如水下、细胞显微镜)和模糊的情况」,并展示了作为 CV 基本模型的巨大潜力。
DINOv2:可实现深度估计、语义分割和实例检索等功能,还能准确从视频中识别出物体。
百度UFO2.0:行业最大 170 亿参数视觉多任务模型,覆盖人脸、人体、车辆、商品、食物细粒度分类等 20+ CV 基础任务,单模型 28 个公开测试集效果 SOTA。
盘古CV大模型:基于模型大小和运行速度需求,自适应抽取不同规模模型,AI应用开发快速落地。使用层次化语义对齐和语义调整算法,在浅层特征上获得了更好的可分离性,使小样本学习的能力获得了显著提升,达到业界第一。
由于CV领域的任务本身就更加复杂,很少有像ChatGPT一样可以使用各种场景的通用大模型。
但从本质上看,ChatGPT是一个生成式语言模型,而在CV领域也有生成式的大模型,例如Disfussion,Midjourney, MAE。同时CV还有很多非生成式的应用,例如目标检测、图像分割、实例分割、空间深度估计等,基于此我认为视觉大模型是那些参数量大、针对某种或几种特定任务上的模型。
模型部署技术
- 模型压缩:CNNpack:在频域上的模型压缩技术(NIPS 2016)
- 模型蒸馏:基于对抗学习的知识蒸馏方案(AAAI 2018)
- 模型剪枝:进行自动剪枝和量化(SIGKDD 2018),针对生成模型的协同进化压缩算法(ICCV 2019)
AI推理框架
借助成熟的AI部署框架,我们可以方便地进行模型部署,而不需要了解推理加速、适配多平台硬件等细节。
Nvidia TensorRT: https://github.com/NVIDIA/TensorRT
Pytorch Libtorch: https://pytorch.org/cppdocs/installing.html
百度飞浆FastDeploy:https://github.com/PaddlePaddle/FastDeploy
腾讯NCNN:https://github.com/Tencent/ncnn
TensorRT详细入门指北,如果你还不了解TensorRT,过来看看吧!
AI推理框架对比–OpenVINO、TensorRT、Mediapipe
边缘设备部署
- 基础平台开发:深度学习分析引擎、业务中台、管理平台;
- 模型转换、验证及优化:使用硬件平台厂商提供的模型转换工具套件将caffe、tensorflow、pytorch、mxnet、darknet、onnx等模型转换为目标平台模型,必要时进行模型量化以及模型finetune;对不支持的模型或层,自定义算子、插件实现
- 视频结构化引擎代码适配:主要是视频流及图片编解码、推理等模块,任务管理、流程控制、前后处理等其他代码通常都是跨平台的;
- 交叉编译及测试:使用交叉编译工具链编译及调试代码,交叉编译工具工具链主要包括2部分内容,linaro gcc g++编译及调试器和包含了目标平台系统环境及软件库的所有代码文件;
- 业务代码实现:针对不同场景的业务需求开发业务逻辑处理代码;
- 系统部署:通常使用docker部署,使用docker-compose编排多个docker容器或使用K8S管理多个分布式节点。
英伟达设备部署
训练框架训练模型->模型转化为ONNX格式->ONNX格式转化为其他格式(NCNN,TNN,MNN的模型格式)->在对应的推理框架中部署
假设我们的模型是使用pytorch训练,在英伟达GPU部署:
- Pytorch->ONNX->trt onnx2trt
- Pytorch->trt torch2trt
- Pytorch->torchscipt->trt trtorch
常见的服务器部署搭配:
- triton server + TensorRT/libtorch
- flask + Pytorch
- Tensorflow Server
昇腾设备部署
下面的博客中使用华为昇腾显卡、CANN计算架构、MindSpore深度学习框架来部署LLM,是一篇非常详细的国产化适配实践案例。
大模型国产化适配2-基于昇腾910使用ChatGLM-6B进行模型推理
注意事项
- 昇腾推理服务器不支持训练,模型训练需要使用训练类型服务器。
- Ascend 310只能用作推理,MindSpore支持在Ascend 910训练,训练出的模型要转化为OM模型用于Ascend 310上进行推理。
- 目前华为昇腾主要还是运行华为自家闭环的大模型产品。
- 任何公开模型都必须经过华为的深度优化才能在华为的平台上运行。而这部分优化工作严重依赖于华为,进度较慢。
- 目前昇腾芯片对于Pytorch/TensorFlow等第三方框架的支持很差,如果需要适配最新出来的大模型,使用起来困难重重。
混合AI是AI的未来
在这个部分,主要对高通公司发表的“混合AI是AI的未来”白皮书进行总结,虽然高通是出于自己的商业目的发表的,但是其中对混合AI、终端AI的描述还是挺详细的。
随着生成式AI(AIGC)模型的快速发展,对计算基础设施提出了极高的需求,高通认为未来的AI应用模式,尤其是AIGC应用应该是混合式AI模式,即终端和云端协同工作,在适当的场景和时间下分配AI计算的工作负载,高效利用资源。
为什么是混合AI
混合AI架构(或仅在终端侧运行AI),能够在全球范围带来成本、能耗、性能、隐私、安全和个性化优势。
- 生成式AI模型使用量和复杂性的不断增长,仅在云端进行推理并不划算。因为数据中心基础设施成本,包括硬件、场地、能耗、运营、额外带宽和网络传输的成本将持续增加。
- 与云端相比。边缘终端能够以很低的能耗运行生成式AI模型,尤其是将处理和数据传输相结合时。
- 在混合AI架构中,终端侧AI处理十分可靠,能够在云服务器和网络连接拥堵时,提供媲美云端甚至更佳的性能。
- 终端侧AI从本质上有助于保护用户隐私,因为查询和个人信息完全保留在终端上。
混合式AI的场景
- 以终端作为中心
例如,如果当前AI应用比较轻量级,则可以主要放在终端设备上跑,遇到更复杂的问题由判决器决定是否放在云端跑;
- 以终端作为感知
终端负责语音转文字、文字转语音等模型,在云端跑LLM;
- 云边协同
终端用一个轻量的LLM预测几个词,传给云端的大型LLM给出一个近似解的判断;
终端能否支撑起AIGC大模型
性能十分强大的生成式AI模型正在变小,同时终端侧处理能力正在持续提升,在终端部署大模型是可行的。
丰富的生成式AI功能,这些功能的模型参数在10亿至100亿之间。在上个月发布的高通骁龙8Gen3芯片最多可以支持10B参数。
像Stable Diffusion图像生成模型可以实现部署,且性能和精确度达到与云端处理类似的水平;Meta推出的开源LLM:Llama2(7B)也能实现部署。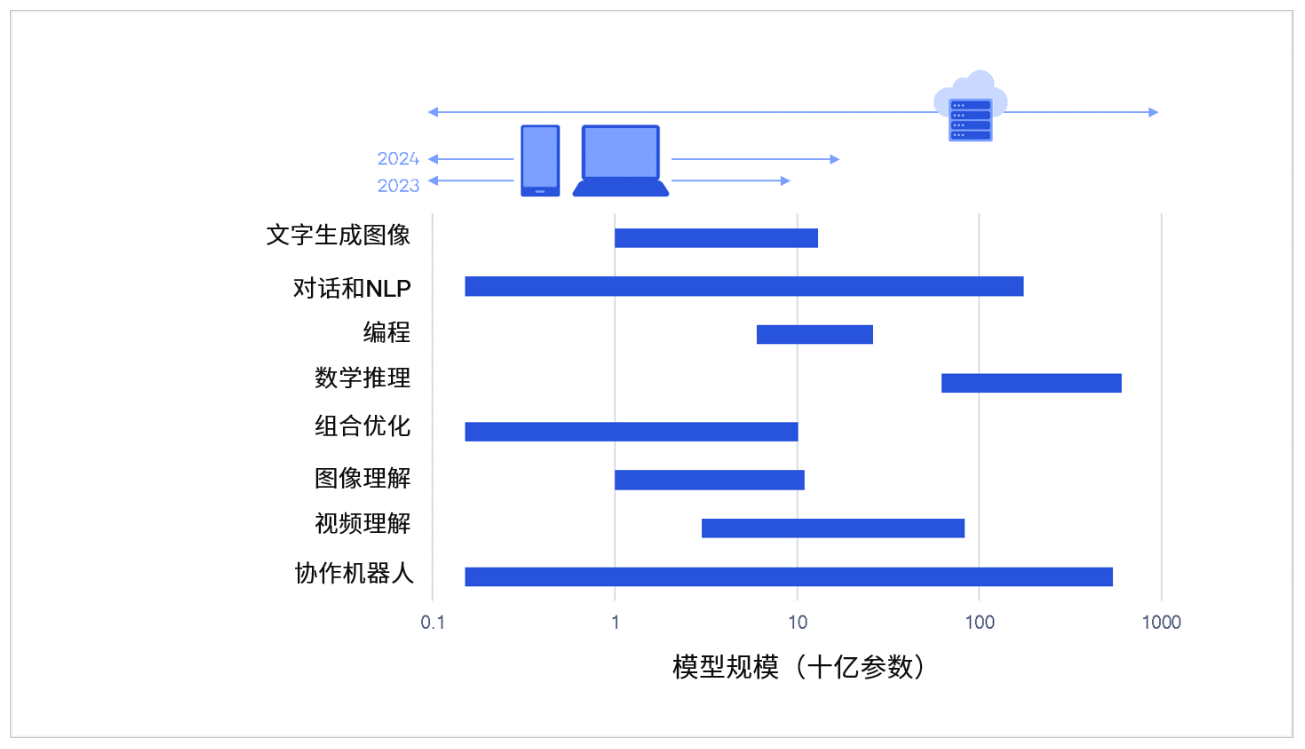
Ref
白夜:一文看懂AI项目流程及边缘设备开发
边缘部署大模型
轻量级的AI模型库
LLMs survey
What is LLMs - Large Language Models? - Hopsworks
将深度学习模型部署到手机上有什么成熟的解决方案吗? - 知乎
GitHub - PaddlePaddle/FastDeploy
Qualcomm-美国高通公司网站